Scouter는 오픈소스 apm(Application Performance Management)으로써 성능 요소를 모니터링하고 관리 application이다.
성능 정보는 일반적으로 Process CPU, Heap Memory, GC, Datasource ConnectionPool, ThreadPool, Request Time, Response Time, TPS등 다양한 정보를 본인이 원하는 정보를 선택하여 모니터링 할 수 있습니다.
대량의 데이터가 수집 되고 상세 프로파일링을 수행하여 특정 메소드, 수행 쿼리 지정 구분 하여 모니터링이 가능하다.
참조 자료
gunsdevlog.blogspot.com/2017/07/scouter-apm-1.html
-Scouter 다운로드
이 설치는 서버OS가 windows 기준 입니다.
1.Scouter 릴리즈 페이지에서 최신버전을 다운 받는다.
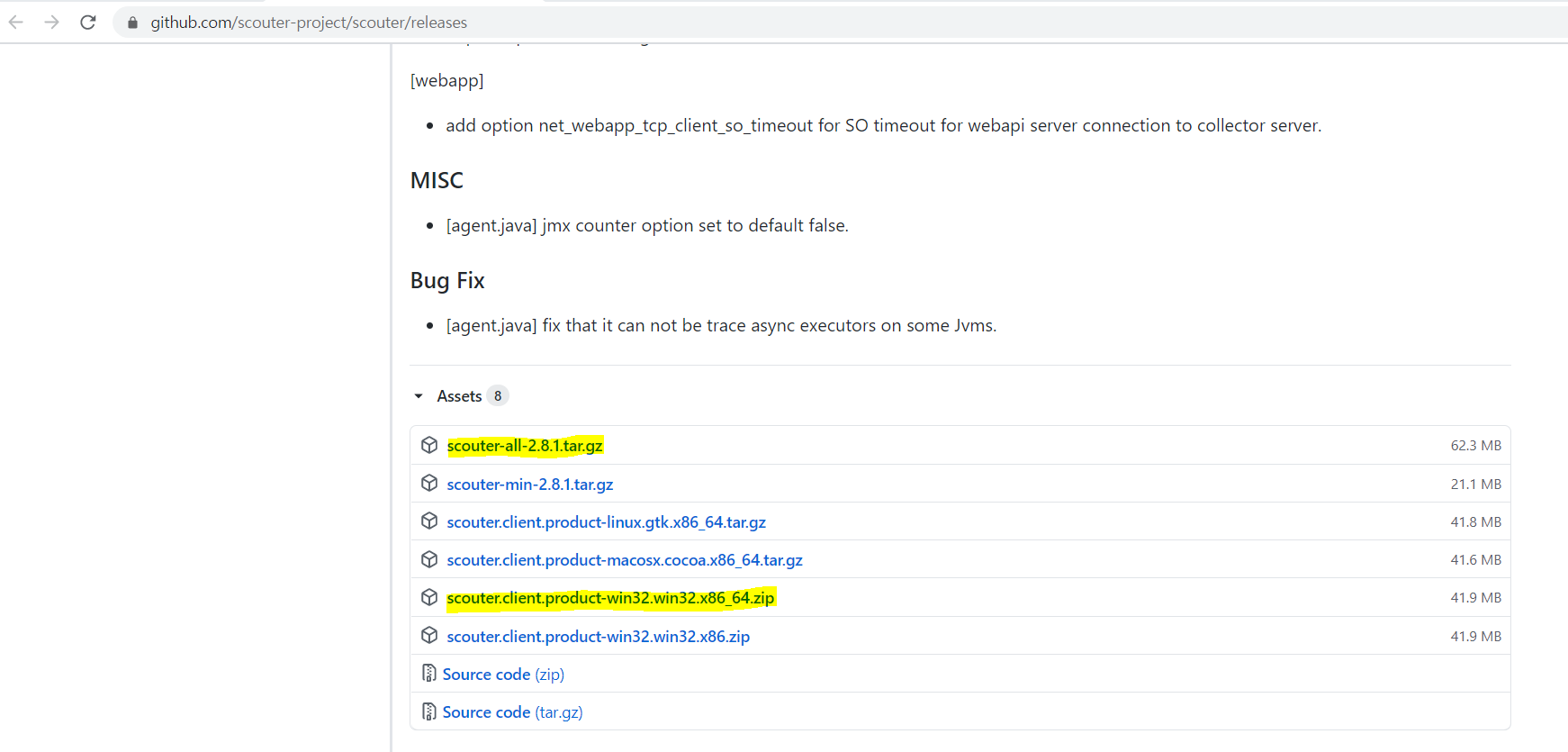
https://github.com/scouter-project/scouter/releases
2. scouter-all-[version].tar.gz 을 받는다.
-Scouter Collector와 Agent를 포함하는 압축 파일입니다.
받아서 서버에 C:드라이브에 둡니다.
3. scouter.client.product-[os].tar.gz 을 받는다.
- Client(Viewer) 프로그램입니다. 내가 모니터링할 내컴퓨터 에 둡니다.
-Scouter Server 설치 및 가동
1.서버에 scouter-all-[version].tar.gz 의 압축을 풀어줍니다. 압축을 푼 Scouter 폴더만 C: 드라이브 위치에 둡니다.
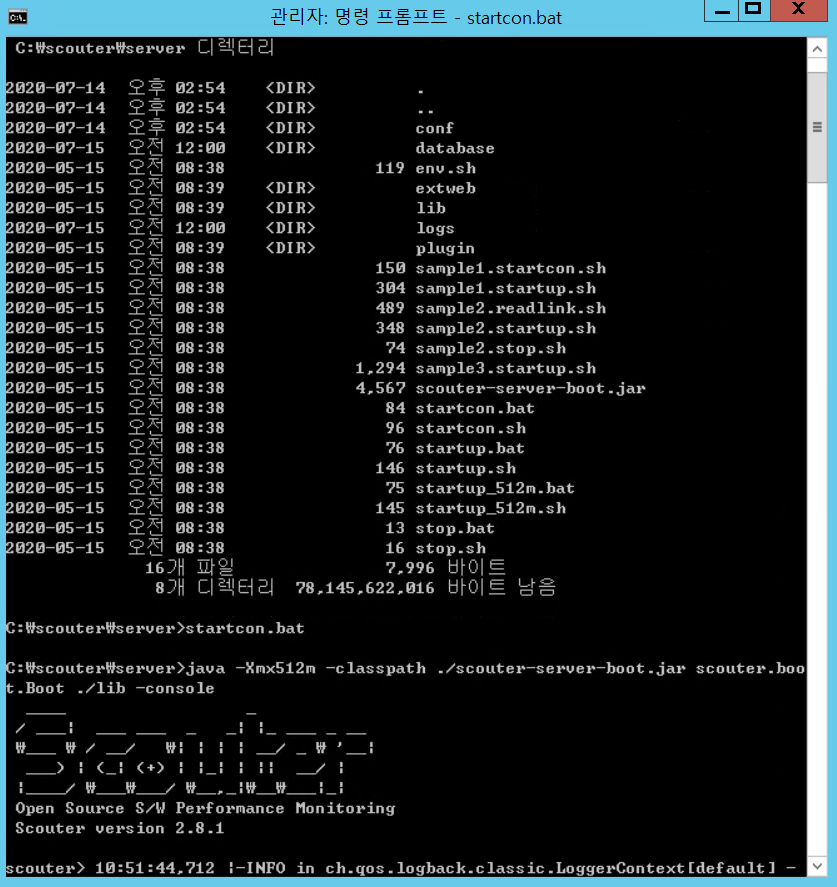
2.서버에서 CMD 창을 열고 scouter 디렉터리에 server 디렉터리 로 접근해 start.bat 를 쳐서 실행 해주면 scouter server 모듈이 기동 됩니다.
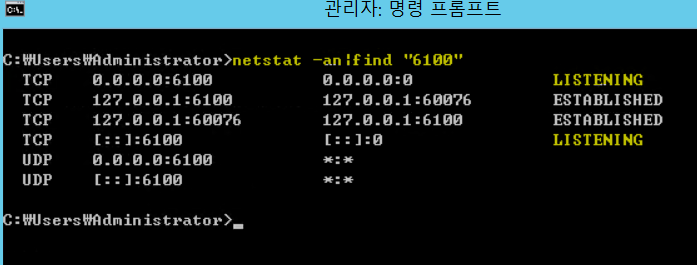
3.CMD창에 netstat -an|find "6100" 치서 아래와 같이 나오면 정상기동 확인 된 것 입니다.
- Scouter Client 실행
1.내컴퓨터 아무 곳에 scouter.client.product-[os].tar.gz의 압축을 풀고 실행합니다.
2. 접속할 Scouter Serve의 IP나 도메인을 입력합니다.기본 포트는 6100, ID와 Password를 입력합니다
. 기본값 : admin / admin
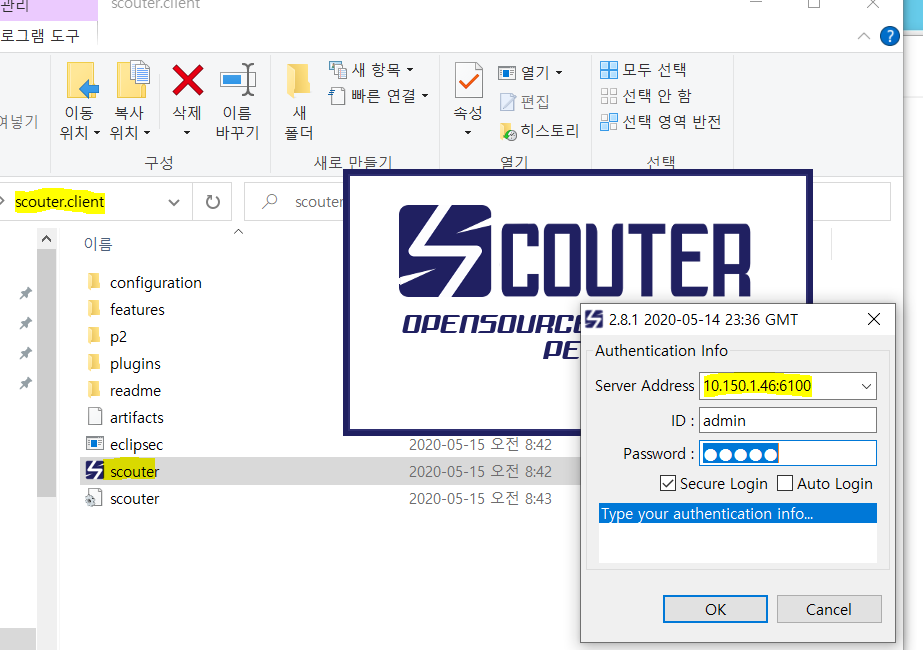
3. Collector에 접속되면 좌측 상단의 Object-View에서 Collector 서버 하나가 있는 것을 확인할 수 있습니다.
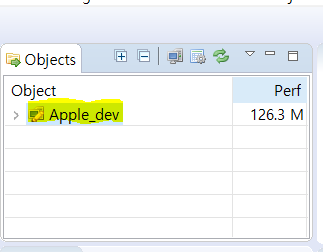
-Scouter Agent 실행
1.Host Agent 실행 전에 먼저 Collector 접속 설정이 필요 해당 위치 - [scouter-dir]/agent.host/conf/scouter.conf 파일을 편집기로 열어 net_collector_ip에는 Collector 접속 IP나 도메인을 기입
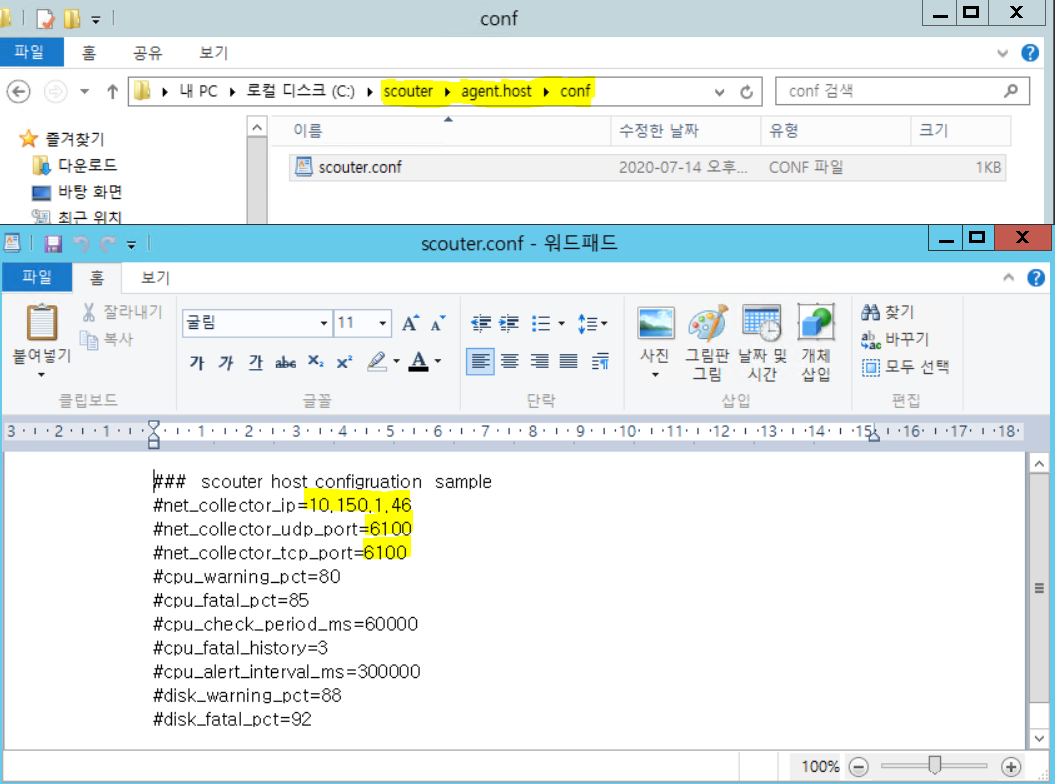
2.Host Agent를 시작한다. -CMD를 열어 scouter 디렉터리에 agent.host 디렉터리 로 접근해 host.bat 를 쳐서 실행 해주면 Host Agent 수행 됩니다.
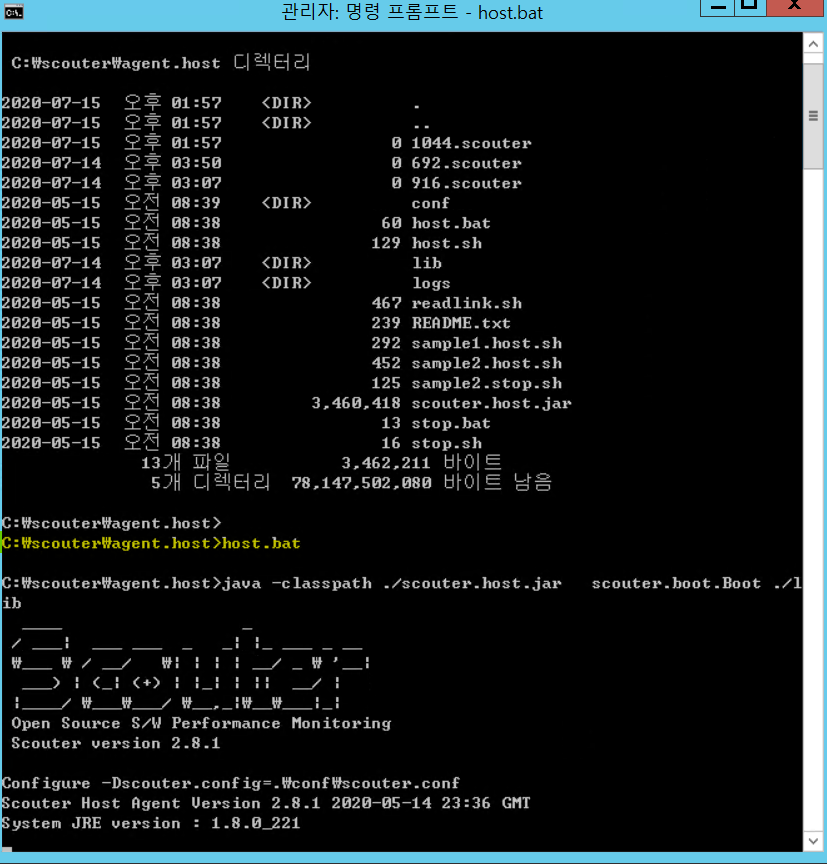
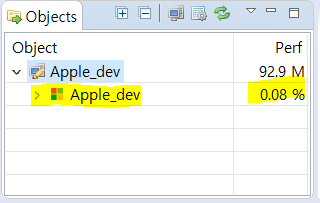
3.Host Agent가 잘 실행되었다면, 앞에서 실행한 Scouter Client에서 Object view 에 하위가 뜬다 저기 %는 CPU점유량이다.
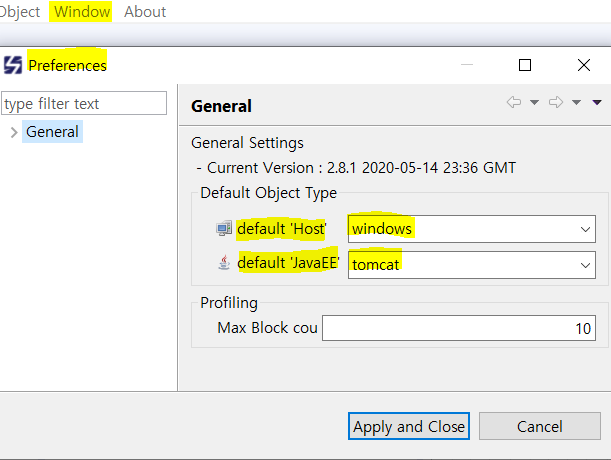
4.Client의 메뉴중 환경설정(Windows -> Preferences) 메뉴로 들어가서 default ‘Host’ 를 windows 로 default ‘javaEE '는 tomcat으로 설정한다. 그럼 CPU 모니터링이 가능하다.
-Java Agent 실행 (이클립스 톰캣실행시)
Java Agent는 단독으로 실행되는 것이 아니라, 모니터링할 Java Program이 실행될 때 attach되어 모니터링을 수행합니다. 따라서 실행하는 Java Program에서 scouter agent를 인식할 수 있도록 명령 행 옵션을 설정해야 합니다.
즉 톰캣시 시작 하는 곳에 자바설정을 잡아 주면 된다.
1.테스트 서버는 이클립스에서 톰캣을 실행 시켜주니 이클립스 서버부분에서 설정 부분을 해준다.
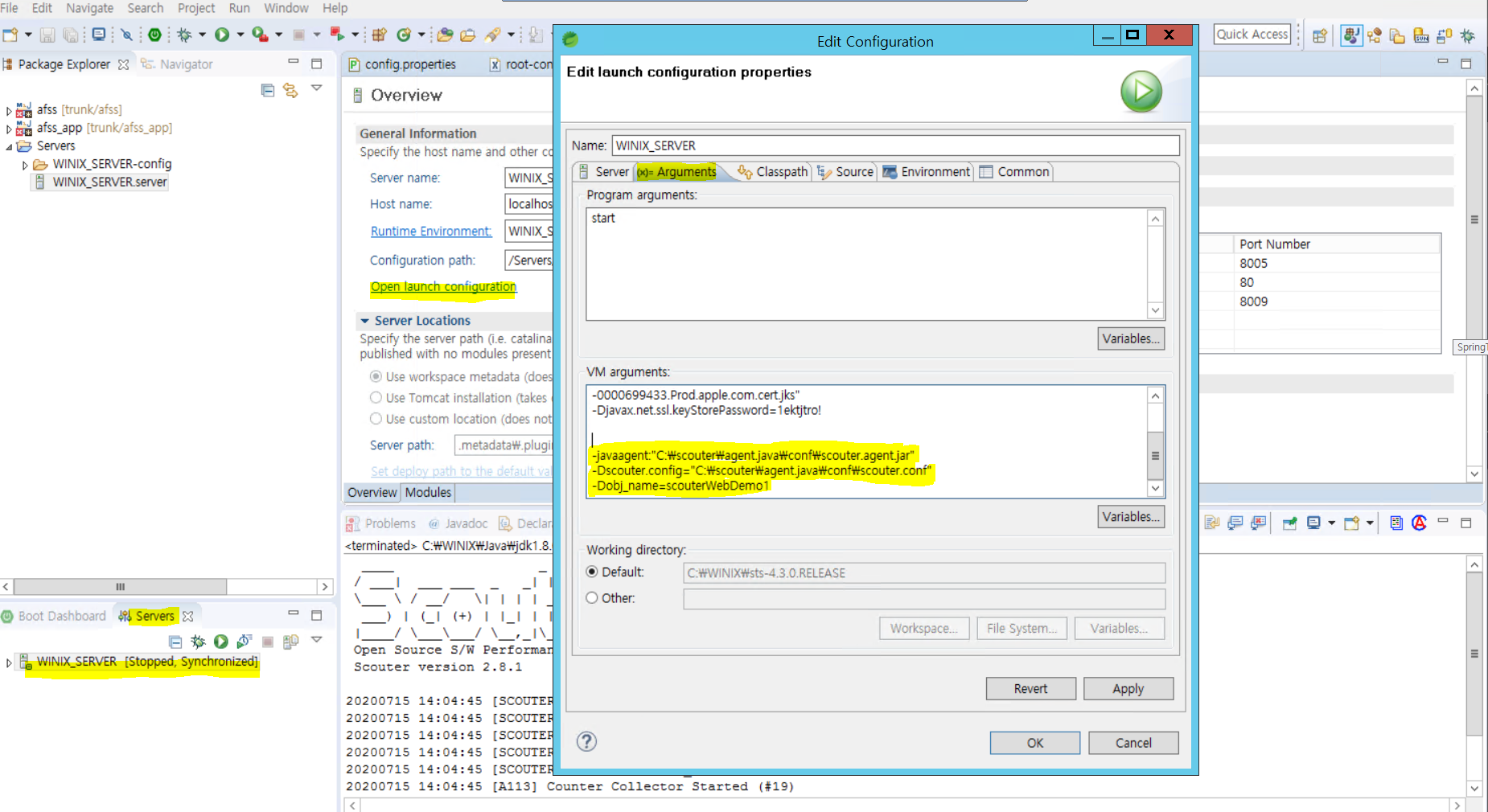
2.Server에 tomcat부분 더블클릭 하면 페이지가 뜬다. 다음 Open launch configuration 을 클릭해 edit가 뜨면 Arguments탭에 가운데 VM arguments 부분에 해당 자바설정 부분을 넣는다.(경로확인후)
-javaagent:"C:\scouter\agent.java\conf\scouter.agent.jar"
-Dscouter.config="C:\scouter\agent.java\conf\scouter.conf"
-Dobj_name=scouterapptestWeb
3. 서버를 재시작 한다. 그럼 view 에 모든 데이터가 보이기 시작한다.
-Java Agent 실행
Java Agent는 단독으로 실행되는 것이 아니라, 모니터링할 Java Program이 실행될 때 attach되어 모니터링을 수행합니다. 따라서 실행하는 Java Program에서 scouter agent를 인식할 수 있도록 명령 행 옵션을 설정해야 합니다.
즉 톰캣시 시작 하는 곳에 자바설정을 잡아 주면 된다.
-1.설치 톰캣 시
. Tomcat bin 경로로 가서 Tomcat8w 클릭하며 Properties 가 뜨면 java 탭에 가운데 Java Options 에 아래 설정을 붙여 넣는다. (경로확인해보고)
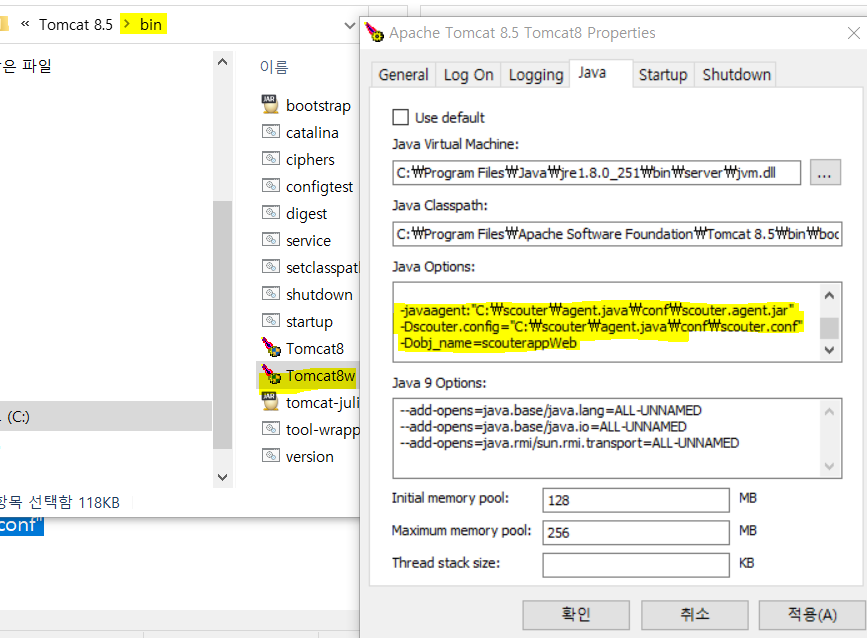
-2.비 설치 톰캣 시
Tomcat bin 경로로 가서 Catalina.bat 편집하기해 “JAVA_OPTS”부분에 뒤쪽으로 아래 설정을 붙여 넣는다. (경로확인해보고)
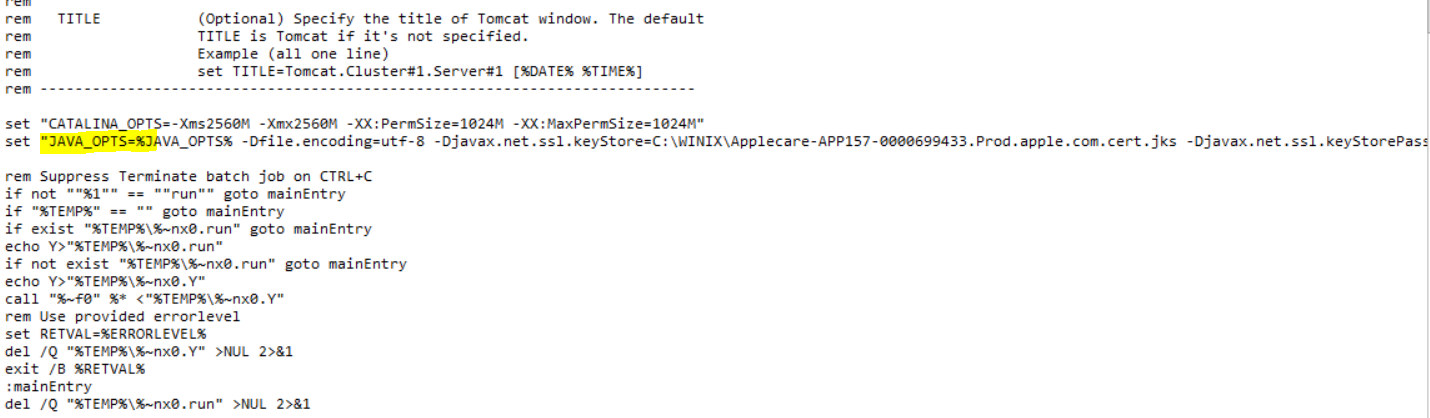
-javaagent:"C:\scouter\agent.java\conf\scouter.agent.jar"
-Dscouter.config="C:\scouter\agent.java\conf\scouter.conf"
-Dobj_name=scouterapptestWeb
3. 서버를 재시작 한다. 그럼 Client view 에 모든 데이터가 보이기 시작한다.
이렇게 하면 모니터링이 가능하다. 짜잔!!!
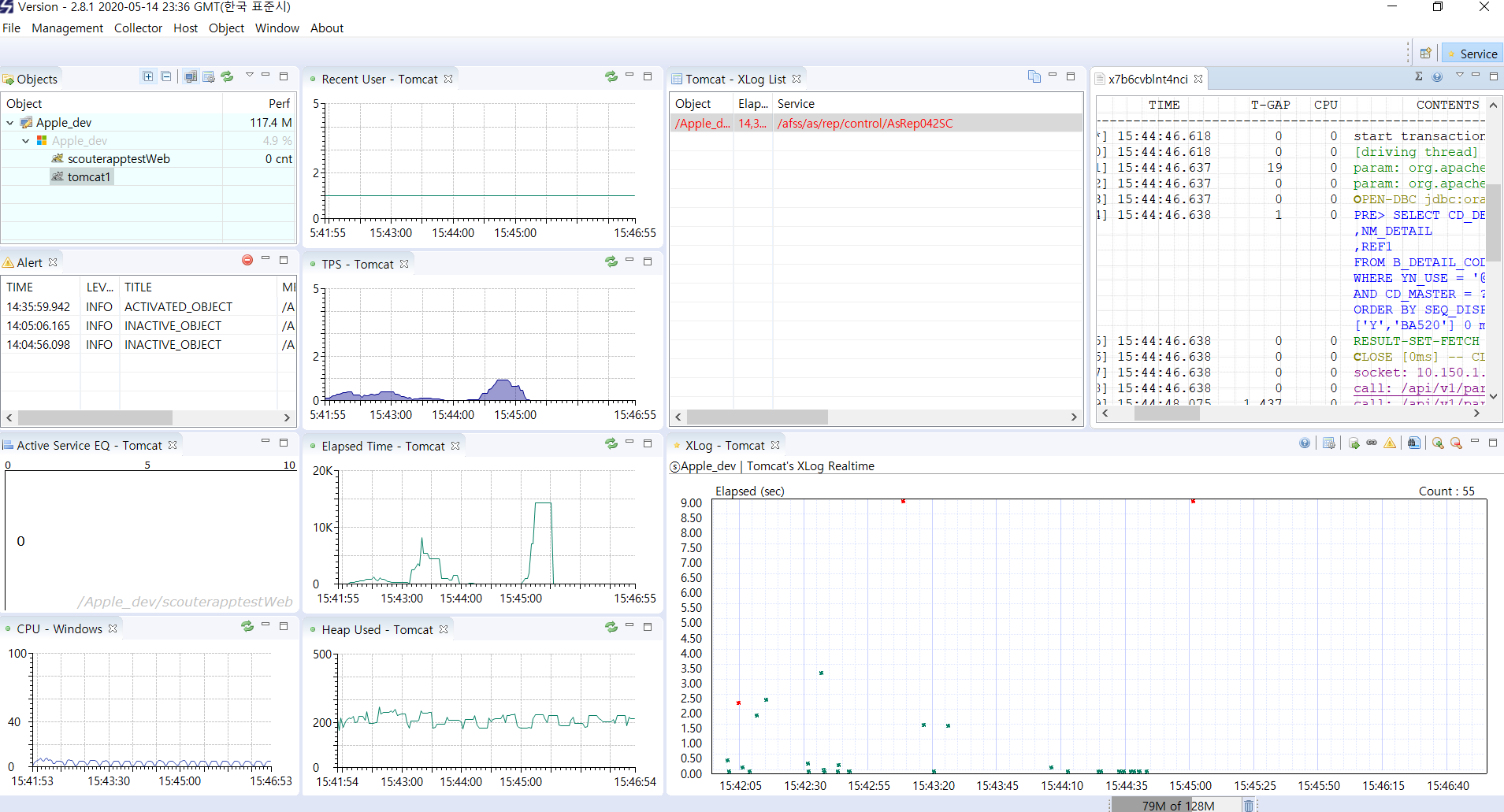
이제 scouter 뷰 켜놓고 이상 있으면 확인 하면 된다!!
감사합니다.
'스터디' 카테고리의 다른 글
| Flutter/플러터 MySQL로 어플 앱 만들기 1 (641) | 2023.05.23 |
|---|---|
| 리눅스 root 비밀번호 변경 (1284) | 2019.01.16 |
| 허브, 스위치, 라우터의 진화과정으로 이해하는 인터넷 (357) | 2018.08.08 |
| L2, L3, L4, L7 스위치란 무엇인가? (967) | 2018.08.08 |
| 정보처리기사 알고리즘 기초 (7) | 2018.05.09 |